

Federated learning enables users to train a model without sending raw data to a central server, thus avoiding the collection of privacy-sensitive data. Often this is done by learning a single global model for all users, even though the users may differ in their data distributions. For example, users of a mobile keyboard application may collaborate to train a suggestion model but have different preferences for the suggestions. This heterogeneity has motivated algorithms that can personalize a global model for each user.
However, in some settings privacy considerations may prohibit learning a fully global model. Consider models with user-specific embeddings, such as matrix factorization models for recommender systems. Training a fully global federated model would involve sending user embedding updates to a central server, which could potentially reveal the preferences encoded in the embeddings. Even for models without user-specific embeddings, having some parameters be completely local to user devices would reduce server-client communication and responsibly personalize those parameters to each user.
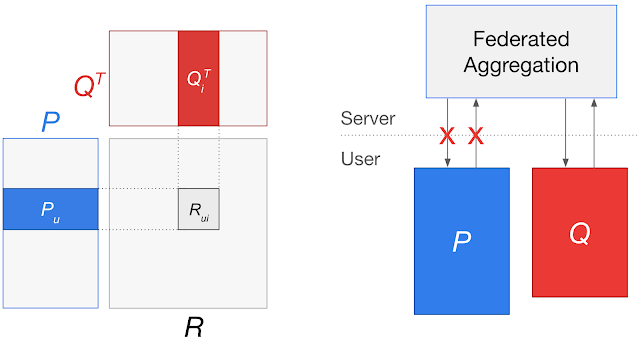 |
| Left: A matrix factorization model with a user matrix P and items matrix Q. The user embedding for a user u (Pu) and item embedding for item i (Qi) are trained to predict the user’s rating for that item (Rui). Right: Applying federated learning approaches to learn a global model can involve sending updates for Pu to a central server, potentially leaking individual user preferences. |
In “Federated Reconstruction: Partially Local Federated Learning”, presented at NeurIPS 2021, we introduce an approach that enables scalable partially local federated learning, where some model parameters are never aggregated on the server. For matrix factorization, this approach trains a recommender model while keeping user embeddings local to each user device. For other models, this approach trains a portion of the model to be completely personal for each user while avoiding communication of these parameters. We successfully deployed partially local federated learning to Gboard, resulting in better recommendations for hundreds of millions of keyboard users. We’re also releasing a TensorFlow Federated tutorial demonstrating how to use Federated Reconstruction.
Federated Reconstruction
Previous approaches for partially local federated learning used stateful algorithms, which require user devices to store a state across rounds of federated training. Specifically, these approaches required devices to store local parameters across rounds. However, these algorithms tend to degrade in large-scale federated learning settings. In these cases, the majority of users do not participate in training, and users who do participate likely only do so once, resulting in a state that is rarely available and can get stale across rounds. Also, all users who do not participate are left without trained local parameters, preventing practical applications.
Federated Reconstruction is stateless and avoids the need for user devices to store local parameters by reconstructing them whenever needed. When a user participates in training, before updating any globally aggregated model parameters, they randomly initialize and train their local parameters using gradient descent on local data with global parameters frozen. They can then calculate updates to global parameters with local parameters frozen. A round of Federated Reconstruction training is depicted below.
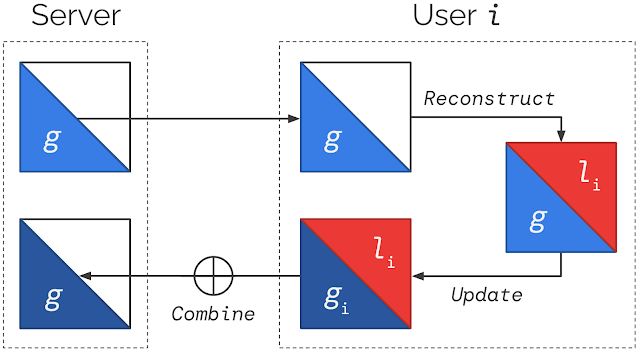 |
| Models are partitioned into global and local parameters. For each round of Federated Reconstruction training: (1) The server sends the current global parameters g to each user i; (2) Each user i freezes g and reconstructs their local parameters li; (3) Each user i freezes li and updates g to produce gi; (4) Users’ gi are averaged to produce the global parameters for the next round. Steps (2) and (3) generally use distinct parts of the local data. |
This simple approach avoids the challenges of previous methods. It does not assume users have a state from previous rounds of training, enabling large-scale training, and local parameters are always freshly reconstructed, preventing staleness. Users unseen during training can still get trained models and perform inference by simply reconstructing local parameters using local data.
Federated Reconstruction trains better performing models for unseen users compared to other approaches. For a matrix factorization task with unseen users, the approach significantly outperforms both centralized training and baseline Federated Averaging.
| RMSE ↓ | Accuracy ↑ | |
| Centralized | 1.36 | 40.8% |
| FedAvg | .934 | 40.0% |
| FedRecon (this work) | .907 | 43.3% |
| Root-mean-square-error (lower is better) and accuracy for a matrix factorization task with unseen users. Centralized training and Federated Averaging (FedAvg) both reveal privacy-sensitive user embeddings to a central server, while Federated Reconstruction (FedRecon) avoids this. |
These results can be explained via a connection to meta learning (i.e., learning to learn); Federated Reconstruction trains global parameters that lead to fast and accurate reconstruction of local parameters for unseen users. That is, Federated Reconstruction is learning to learn local parameters. In practice, we observe that just one gradient descent step can yield successful reconstruction, even for models with about one million local parameters.
Federated Reconstruction also provides a way to personalize models for heterogeneous users while reducing communication of model parameters — even for models without user-specific embeddings. To evaluate this, we apply Federated Reconstruction to personalize a next word prediction language model and observe a substantial increase in performance, attaining accuracy on par with other personalization methods despite reduced communication. Federated Reconstruction also outperforms other personalization methods when executed at a fixed communication level.
| Accuracy ↑ | Communication ↓ | |
| FedYogi | 24.3% | Whole Model |
| FedYogi + Finetuning | 30.8% | Whole Model |
| FedRecon (this work) | 30.7% | Partial Model |
| Accuracy and server-client communication for a next word prediction task without user-specific embeddings. FedYogi communicates all model parameters, while FedRecon avoids this. |
Real-World Deployment in Gboard
To validate the practicality of Federated Reconstruction in large-scale settings, we deployed the algorithm to Gboard, a mobile keyboard application with hundreds of millions of users. Gboard users use expressions (e.g., GIFs, stickers) to communicate with others. Users have highly heterogeneous preferences for these expressions, making the setting a good fit for using matrix factorization to predict new expressions a user might want to share.
 |
| Gboard users can communicate with expressions, preferences for which are highly personal. |
We trained a matrix factorization model over user-expression co-occurrences using Federated Reconstruction, keeping user embeddings local to each Gboard user. We then deployed the model to Gboard users, leading to a 29.3% increase in click-through-rate for expression recommendations. Since most Gboard users were unseen during federated training, Federated Reconstruction played a key role in this deployment.
Further Explorations
We’ve presented Federated Reconstruction, a method for partially local federated learning. Federated Reconstruction enables personalization to heterogeneous users while reducing communication of privacy-sensitive parameters. We scaled the approach to Gboard in alignment with our AI Principles, improving recommendations for hundreds of millions of users.
For a technical walkthrough of Federated Reconstruction for matrix factorization, check out the TensorFlow Federated tutorial. We’ve also released general-purpose TensorFlow Federated libraries and open-source code for running experiments.
Acknowledgements
Karan Singhal, Hakim Sidahmed, Zachary Garrett, Shanshan Wu, Keith Rush, and Sushant Prakash co-authored the paper. Thanks to Wei Li, Matt Newton, and Yang Lu for their partnership on Gboard deployment. We’d also like to thank Brendan McMahan, Lin Ning, Zachary Charles, Warren Morningstar, Daniel Ramage, Jakub Konecný, Alex Ingerman, Blaise Agüera y Arcas, Jay Yagnik, Bradley Green, and Ewa Dominowska for their helpful comments and support.

